传统DR面临的挑战
当前的灾备系统依然比较复杂,因为灾备包含存储、计算和网络资源,当前的解决方案例如SRM可以完成计算以及存储的恢复,但是网络受限于物理架构,比较难通过SRM实现自动恢复。网络方面具体的问题如下
- 需要在备份站点和主站点建设等同的二层和三层网络架构,维护管理不方便。
- 需要在两个数据中心使用一致的安全策略,使用传统安全解决方案手工配置,管理不方便。
- 在创建安全策略时依赖于IP地址
- 如果主中心和灾备中心建设不一样的网络,在DR时修改虚拟机的IP(IP Re-mapping),则依赖的安全策略都需要进行修改
- 如果要做到主中心和备份中心的计算资源灵活调度,则需要OTV、VPLS等技术实现网络大二层。这样会扩大二层广播域。
DR 场景
- 恢复部分应用
- 恢复一个应用的部分虚拟机,恢复之后要保证其网络正常。
- 恢复整个应用
- 完整恢复一套应用
- 整个站点恢复
- 整个站点,包含 NSX 组件都需要恢复
资源需求
ESXI 和 vCenter
为了确保灾难发生后两个数据中心都可管理,需要分离管理平面,即两个数据中心都有自己的vCenter管理本地的虚拟机。
SRM
SRM依然可以沿用其最佳实践,在使用NSX后,SRM不在需要PortGroup的Mapping,只需要通过NSX创建全局逻辑网络。
Storage Replication
在使用SRM时,Storage Replication是必须用到的,可以使用Array-Based Replication或者vSphere Replication。
如果使用 Array-Based Replication,则需要在SRM上安装SRA(Storage Replication Adapter),让SRM可以与存储阵列通信。
NSX
两个数据中心分别安装自己的NSX manager,关联到本数据中心的vCenter,这时候需要使用Cross-VC NSX解决方案,使用 Universal 逻辑网络。
使用 Cross-VC NSX 时网络有以下特点:
- Cross-VC 可以将二层网络、三层网络以及安全延展到两个数据中心
- Cross-VC 支持 Universal 对象,如:Universal Logical Switch、Universal Distributed Router、Universal DFW等。这些对象在 Primary NSX manager 被创建,可以同步到其他 NSX manager。
- Cross-VC 部署时有一个 Primary NSX manager,其他都是 Secondary NSX Manager。
- Cross-VC 解决方案只能有一个 Universal Controller Cluster,同时控制 Universal 网络和 Local NSX逻辑网络。
- Universal 逻辑网络只能在 Primary NSX manager上进行创建,但是在其他 NSX manager 上可以查看这些配置。
- Cross-VC NSX 支持 Universal DFW 规则,任何在 Universal Section 创建的防火墙规则都可以同步到所有 NSX manager。
- Universal DFW 只支持使用 IP Set、MAC Set、Security Groups(包含 IP Set和 MAC Set)来做防火墙策略
- Universal DLR 在进行 Egress 优化时,需要在两个数据中心分别部署一台 UDLR VM,和本地的 ESG 建立邻居关系。
- 如果 Primary NSX Manager 故障, NSX 网络可以被恢复,配置信息不会丢失
NSX 6.2 及 Egress 流量优化
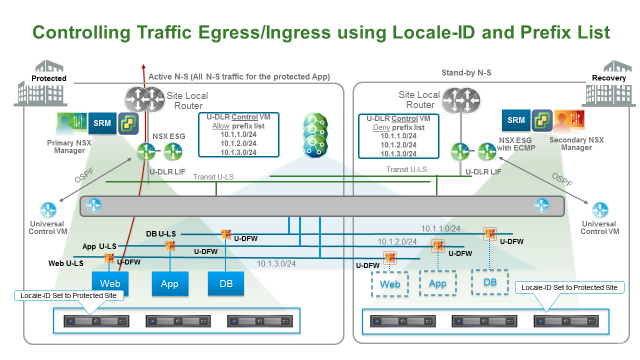
为了避免部分流量在数据中心间的传播,需要进行出流量优化,让本地数据中心产生的流量从本地的出口路由器出去,NSX 为了实现此功能引入了 Locale-ID 的概念,允许流量从关联到的 Locale-ID 的站点出。其特性主要功能如下:
- 默认,Locale-ID 被设置成 NSX Manager UUID,Locale ID 只有在启用 Local Egress 功能时才有效,平时无效。对于 DR 环境,必须做 Local Egress。
- 启用 Local Egress 优化时,Locale-ID 可以基于主机、集群、DLR实例来进行配置。对于 DR 环境,我们通常针对整个集群进行 Locale-ID 配置。
- 对于每个 Universal DLR,需要部署两台虚拟机,一个在主站点一个在备份站点。每个 CVM 和其本地的 ESG 进行邻居关系建立。
- 配有相同 Locale-ID 的主机才能接收到对应 Locale-ID 的 CVM 的路由
预先配置
在开始搭建 DR 环境时,需要预先搭建好 NSX 环境,具体步骤如下:
- 两个独立的站点,之间通过三层网络连接起来
- 每个站点部署下列东西:一套或多套vCenter;ESXi 主机,请注意版本号;SRM,SRM需要按照最佳实践搭建
- 主数据中心搭建 Primary NSX Manager,和主数据中心的 vCenter 做对接。
- 其他数据中心搭建 Secondary NSX Manager
- 在主机数据中心部署三台 Universal Controller
- 主备数据中心使用相同的 Universal Transport Zone,使用相同的 Universal Logical Switch
- 每个站点有自己的 ESG 打通南北通信 - 这是为了做 Local Egress。
- 每个站点有自己的 DLR CVM 和本地的 ESG 做路由邻居。
细节配置
控制 Ingress 和 Egress 流量
有两种办法来控制流量
1、使用 Locale-ID
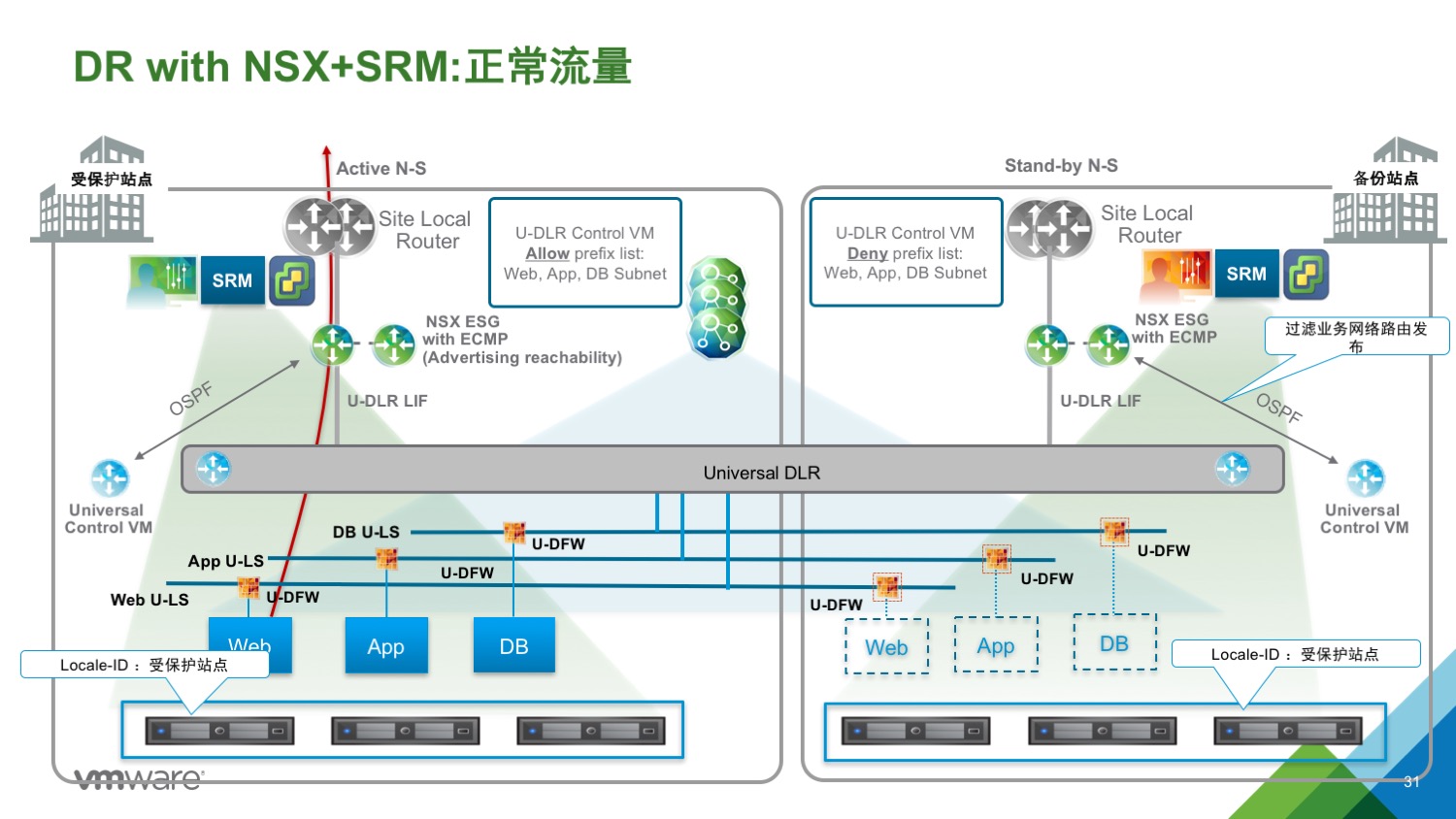
此设计中,在主备数据中心均有自己的 UDLR,两个 UDLR 分别和自己本地的 ESG 建立邻居关系,这样的架构可以让两个数据中心的路由学习分开,进而控制本地流量。但是 Locale-ID 只能控制 Egress 流量,一般可以使用 deny prefix list 来控制路由学习,让备份数据中心的 ESG 不通过备份站点的 UDLR 学习到其关联的业务网络的路由。
- 需要创建两个 Transit Logical switch,两个分别连接本地的 ESG 和本地的 UDLR。
- 每个站点的为 UDLR 创建一个 Control VM,UDLR 与本地的 ESG 建立邻居关系,一旦灾难发生,备份站点的 UDLR CVM 已经和 ESG 建立邻居关系可以正常使用
- Egress 流量:开启 Local Egress,将主备数据中心所有主机的 Locale-ID 设置为主数据中心的 NSX manager UUID
- Ingress 流量:使用路由前缀列表(prefix list),将业务网络只通过给主数据中心的 ESG,不通告给备数据中心的 ESG
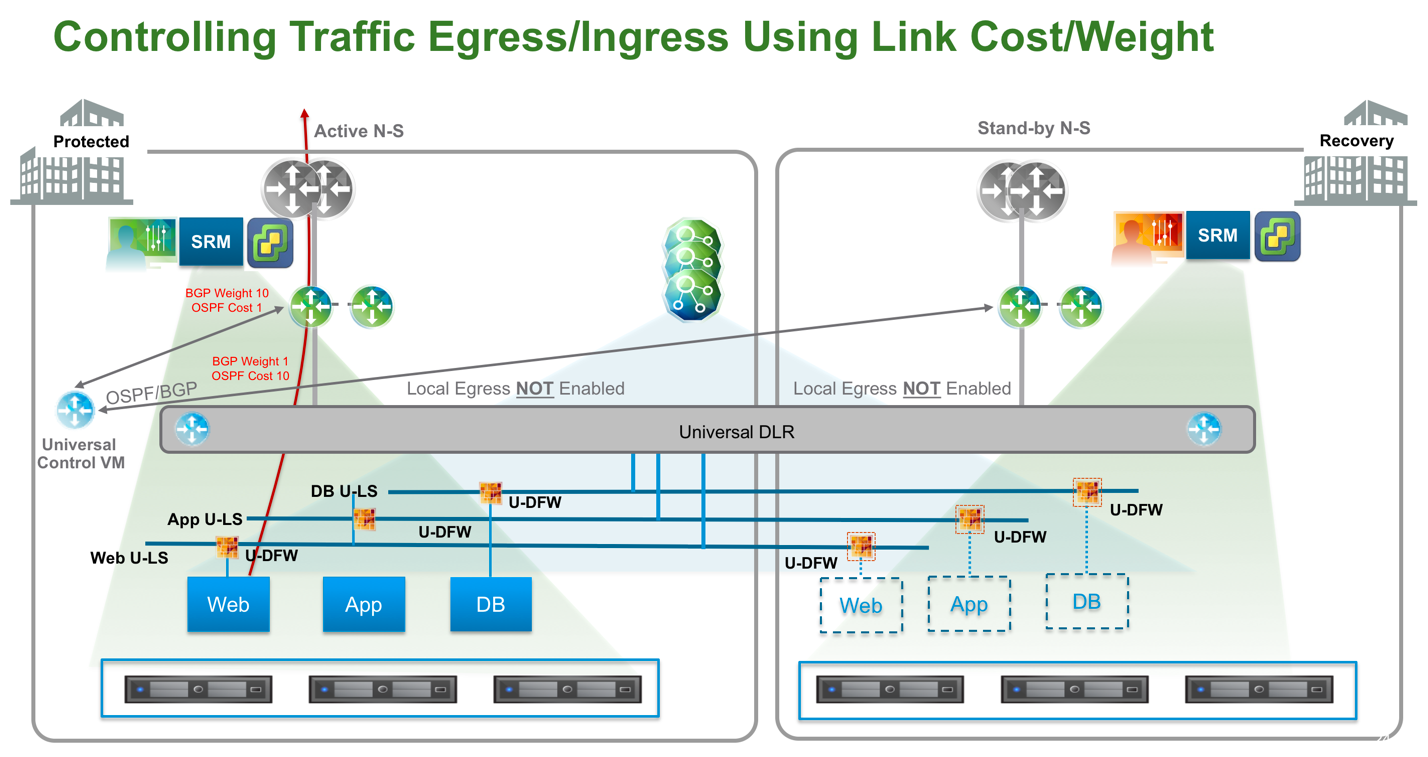
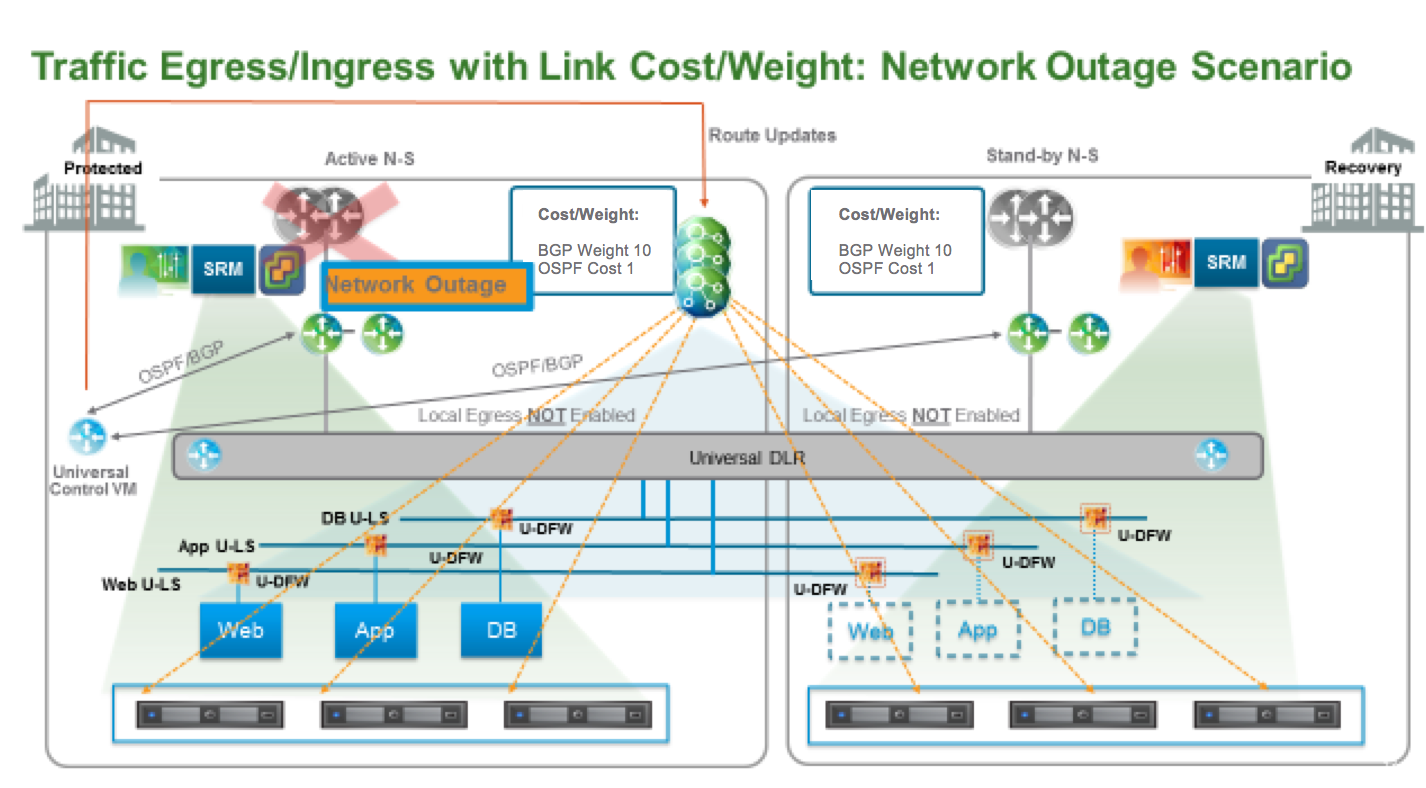
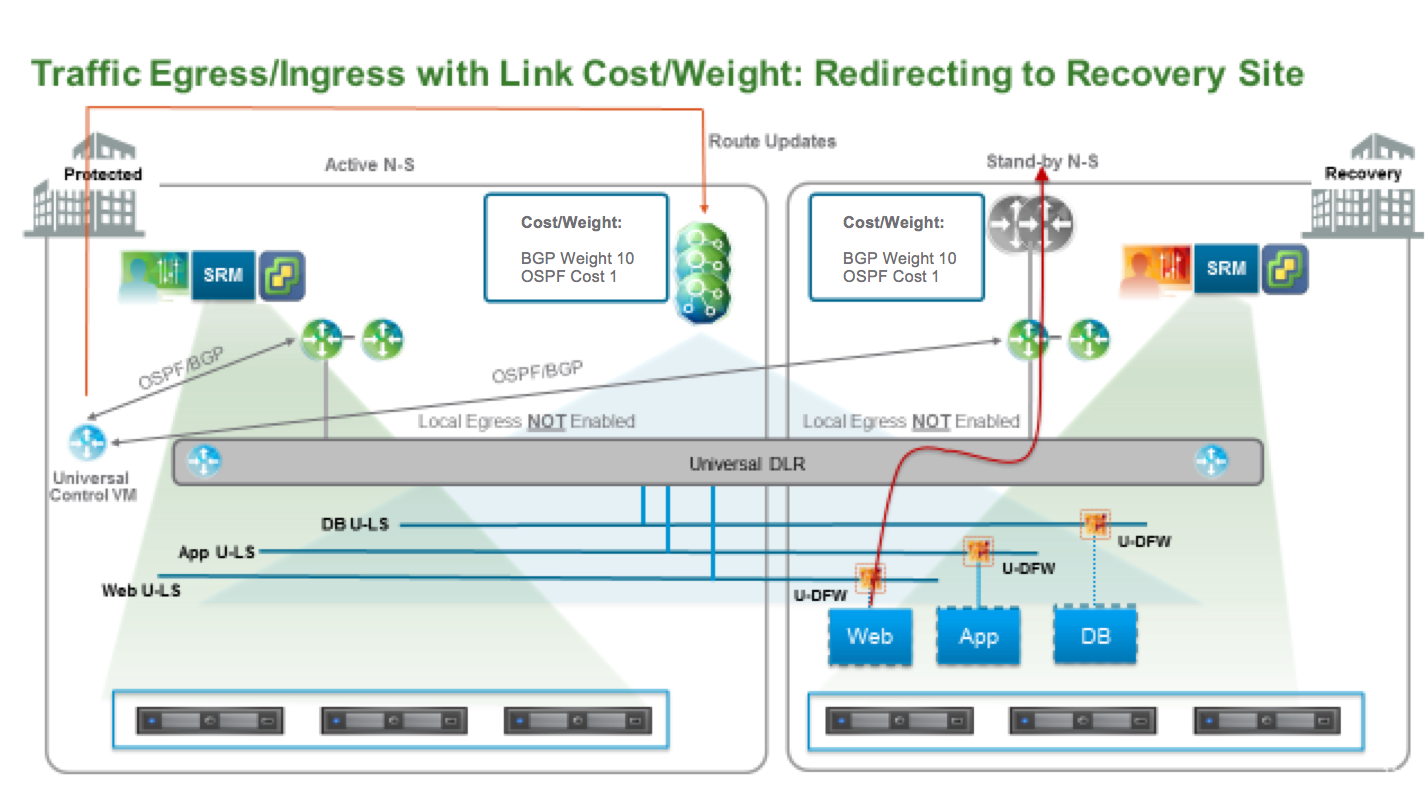
2、使用动态路由调整流量路径
在此设计中,UDLR 存在于两个数据中心,但是只部署一个 UDLR Control VM。只给 UDLR 创建一个 Uplink,和两个站点的 ESG 做邻居。这时候所有主机都能从两个 ESG 收到路由,为了优化 Egress,可以修改动态路由的 Cost。对与 OSPF,Cost 越小路由越优,对于 BGP,Weight 越大路由越优。本例中需要修改 ESG 到 UDLR (BGP:以及外部路由器连接 ESG) 的 Cost 值。
- 只创建一个 Universal Logical Switch 来作为 UDLR 的 Uplink,同时连接两个数据中心的 ESG
- 只在主数据中心部署一个 UDLR CVM。在发生灾难后,CVM 需要重新在备份站点进行部署,重新建立路由关系
- 不需要使用 Local Egress
- 通过动态路由 Cost 调整选路
- Egress 流量:Controller 只会将最佳路由宣告给ESXi 主机,所以此例中,所以流量会从主数据中心出去
- Ingress 流量:调整动态路由 Cost 后,虽然两个数据中心的物理路由器都能收到去往 NSX 逻辑网络的路由,但是只会优先从主数据中心的 ESG 进去,因为其路径最优。
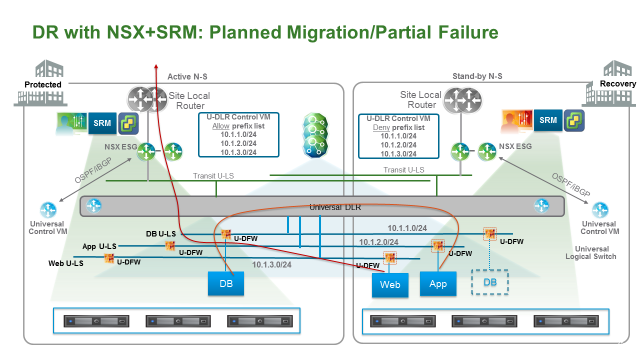
计划迁移/部分应用恢复
大部分企业要求 DR 设计能够满足部分应用恢复或者计划迁移的要求。在这时候,做完恢复后要求恢复的虚拟机不仅能够正常运行,他们还需要与运行在主数据中心的部分虚拟机进行正常通讯。
以下是部分恢复时 SRM 配置步骤:
- 执行部分 failover plan,在此案例中,只恢复 web 和 APP VM,不恢复 DB VM
- 对于 NSX 而言,逻辑网络在两个数据中心是相同的,不需要做任何变更,虚拟机可以随意在两个数据中心进行迁移
- Ingress/Egress 流量:所有南北向流量依然通过主站点进出。
完整应用恢复
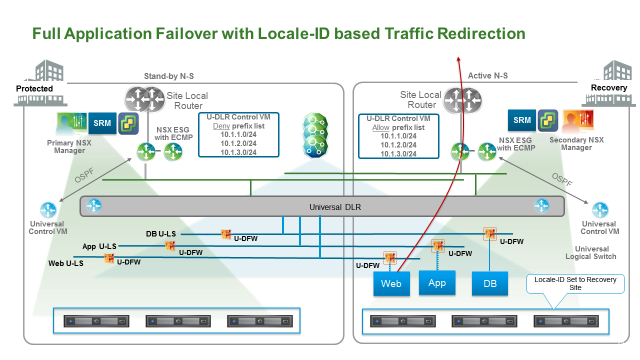
完整应用恢复指将一整套应用(WEB、APP、DB)完整在备份站点恢复。这时候推荐使用 Locale-ID 进行流量路径优化。
下面是完整应用恢复的步骤:
- 执行 SRM 的恢复计划,恢复 WEB、APP 和 DB VM
- 对于 NSX ,只需要调整 Ingress/Egress 流量。
使用 Locale-ID 进行南北向流量调整
- Egress:调整备份站点主机或集群的 UUID,将其改为 Secondary NSX Manager 的 UUID,此操作可以通过 API 或者 UI 执行。
- Ingress:撤销备份站点之前配置的 Prefix List,让外部物理路由器可以通过动态路由学习到去往逻辑网络的路由。同时在主数据中心的 UDLR 设置 Prefix list(通过 UI 或者 API)。
使用动态路由调整南北向流量路径
这种配置模式是全局的,一旦调整会影响所有网段,而使用 Locale-ID 时可以针对每个网段进行流量路径调整(egress使用Locale-ID做本地出,ingress使用Prefix-list 进行网段的对外发布)。
这种设计可以在外部路由器出问题时自动进行切换。
- Egress:如果Uplink故障,动态路由能自动检测故障,触发路由更新。所有流量切换到备数据中心
- Ingress:Ingress流量也会切到备份数据中心,因为主数据中心的外部路由器不能通过主数据中心的ESG来学习到去往逻辑网络的路由。
在下方的故障中,WEB、APP、DB都进行了恢复,网络也自动进行了恢复。
注意只有网络出问题时,灾难恢复可以不进行业务的恢复。
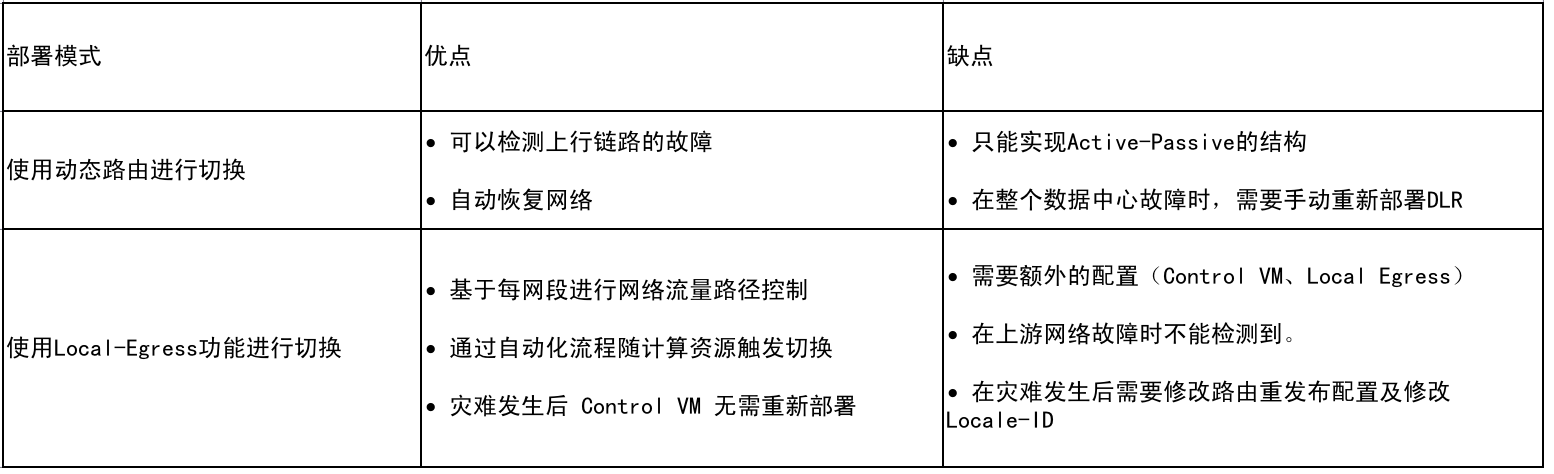
如何选择南北向流量优化方式
参照下图,每种方式都有其优缺点,我们推荐尽量使用动态路由来实现failover,因为其简单并可以自动执行,无需用户干预。Locale-ID 推荐在需要实现更细颗粒度灾备时使用(且主备数据中心网络功能均正常),Locale-ID(+Prefix List)需要手动介入或者使用脚本来修改NSX某些配置。
整个数据中心恢复
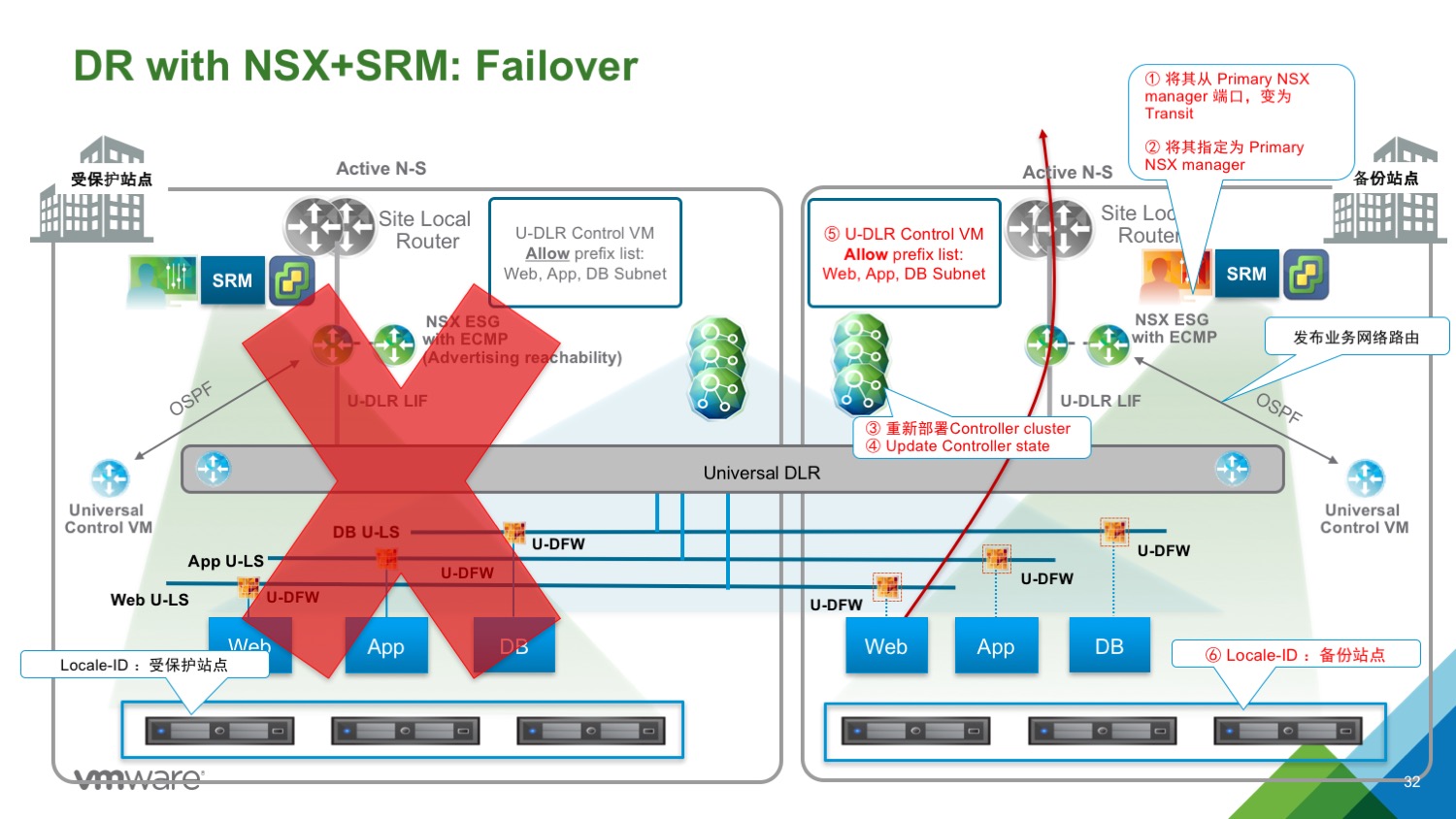
整个数据中心故障牵扯到使用 Recovery Plan 恢复所有应用及 NSX 组件。
具体步骤有:
- 运行 SRM 进行 Recovery Plan
- 假设 NSX Primary manager 和 Universal Controller Cluster 不可访问。
- 作为 SRM 恢复的一部分,虚拟机会自动关联到合适的端口组,主中心的故障不会影响以上操作。
- 在备份站点的 Universal Logical Switch、Universal DLR 和 DLR CVM 不受影响,即使此时 NSX Primary Manager 和 UCC 已经不可访问。
NSX 组件恢复步骤(详情参见参考资料):
1、在备份站点,将 Secondary NSX manager 从 Primary NSX Manager 断开(状态会变为 Standalone)
2、将 Secondary NSX Manager 设置为 Primary 角色
3、在备份站点使用新的 Primary NSX manager 重新部署 NSX Controller 集群(使用新的 IP Pool)
4、同步 Controller 状态(update Controller State)
5、如果使用了 Local Egress 功能,Universal Control VM 已经存在,否则需要重新部署 Universal Control VM
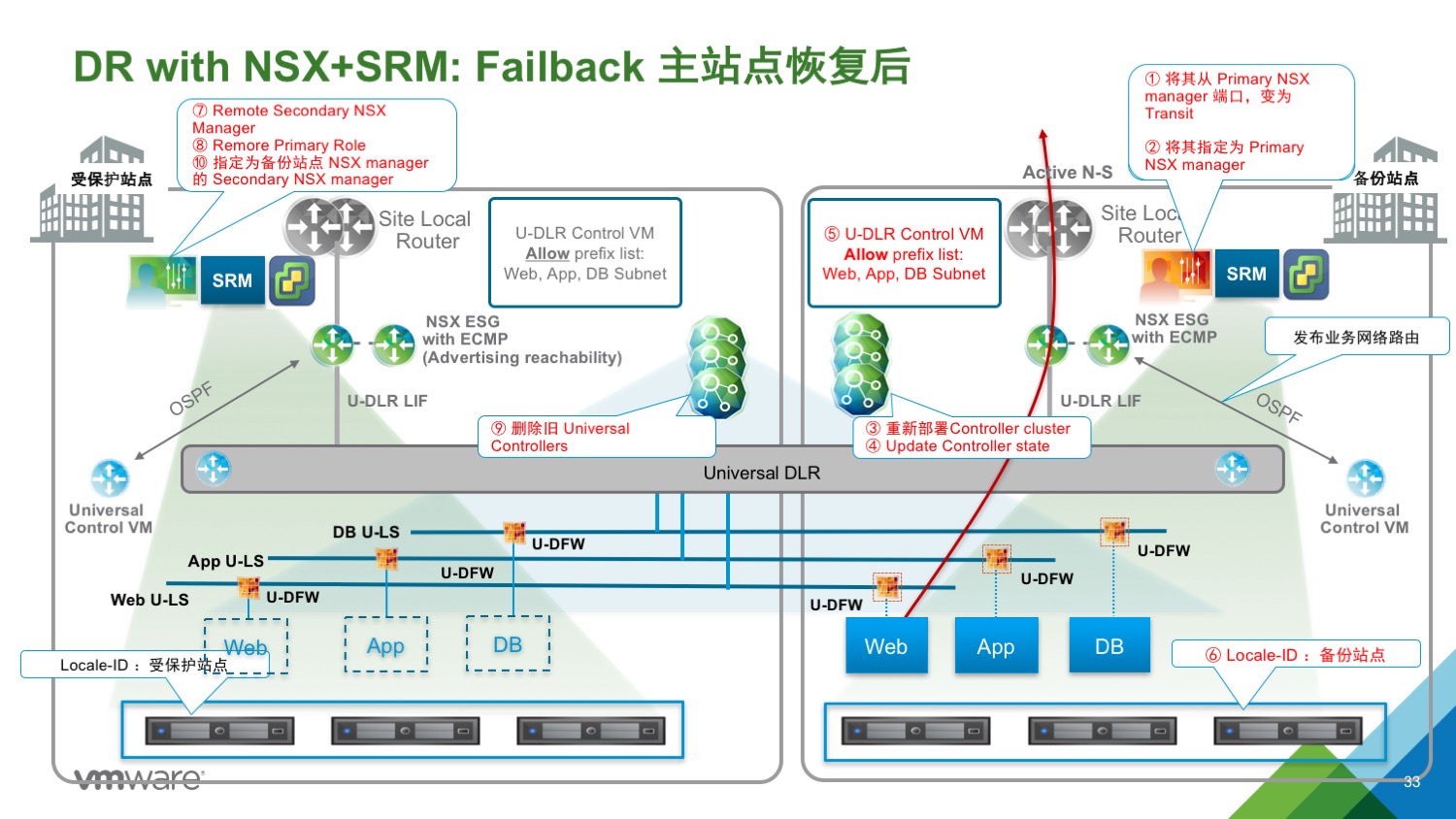
如果原来的主站点恢复了:
6、如果原来的数据中心恢复了,在原来主站点的 NSX manager 上“Remove Secondary NSX Manager”
7、将主站点的 NSX manager 降级为 Transit Role(Remove Primary Role)
8、删除主站点原来的 UCC
9、取决于部署模式,如果需要,删除主站点的 Control VM(因为已经在备份站点部署了新的 Control VM)。
10、将主站点的 Transit role NSX manager 注册为备份站点的 Secondary NSX manager。
到此,VC 组件恢复完整可以正常工作。两个 NSX manager,分别为 Primary 和 Secondary,UCC状态也正常。
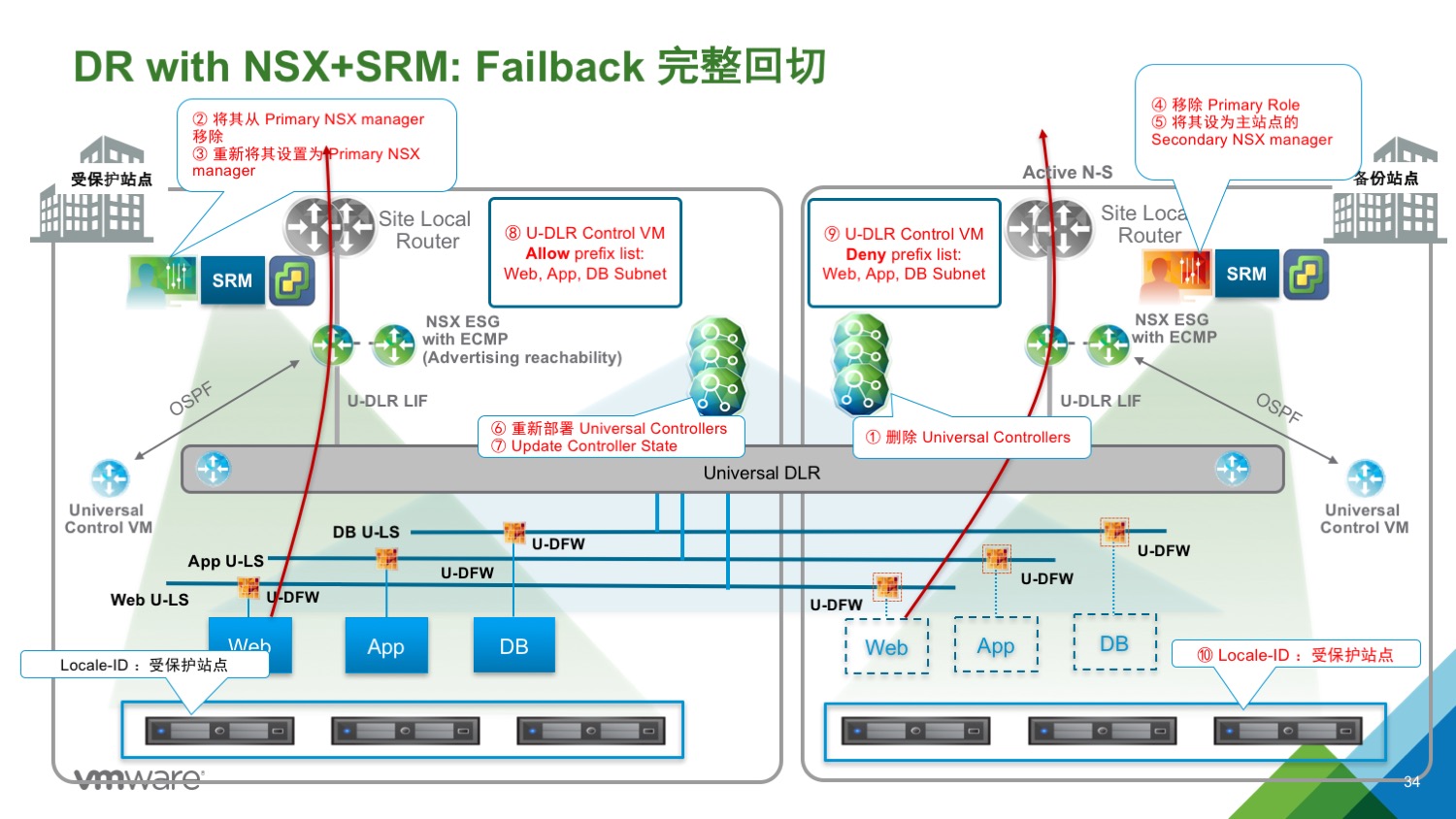
Failback
从 SRM 角度进行 Failback,只需要增加两步骤:
- SRM Failback:SRM 正常运行业务虚拟机的恢复计划,NSX 逻辑网络可以无缝正常运行(只是流量会从备份站点出去)。
- SRM re-protect:类似于重新设置 Protect Plan;只是 NSX Primary Manager 和 UCC 运行在备份站点。
NSX Failback:
1、通过新的 Primary NSX manager 删除备份站点的 UCC
2、将当前 Secondary NSX manager(主站点的NSX manager) 从 Primary NSX manager 移除
3、将主站点的 NSX manager 从 Transit 指定为 Primary
4、移除备份站点的 NSX manager Primary role,其将会进入 Transit Role
5、将备份站点的 NSX manager 设定为 Secondary NSX manager
6、在主站点重新部署 Universal Controller Cluster
7、更新 Controller State
8、根据部署模型的不同,决定是否要重新部署 UDLR Control VM
**(更加详细内容请见 Multi-site Options and Cross-VC NSX Design Guide ) **
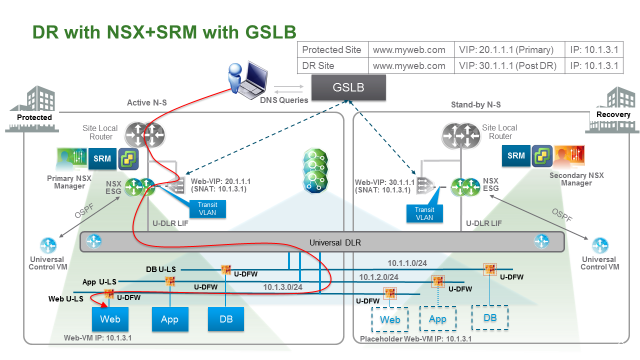
使用 GSLB 全局负载均衡调整 Ingress 流量
虽然使用 NSX 已经能够完整实现灾备,但是在某些时候也推荐使用全局负载均衡来做 Local Ingress 优化。本文不做过细的介绍,关于 GSLB 的最佳实践请参考厂商的文档。
VMware Blog 有一篇较为详细的和 F5 结合做 A/A 架构的文章:点击打开
下面简单描述下引入 GSLB 后如何设计DR:
- 使用 GSLB 时,可以结合 DNS 与站点/应用健康检测。
- 所有面向互联网的 VM 都通过 VIP 访问,这个 VIP 由 SLB 提供。
- WEB VM 的网关依然指向 NSX DLR,出往数据中心依然通过 ESG;数据包从 WEB VM 出来后先到 ESG 做 VXLAN 到 VLAN 解封装,然后通过 Transit VLAN发送给 SLB,SLB 再通过路由将此包发送给 ESG 送往数据中心外部。
- 在主备数据中心部署负载均衡(Active/Standby),为面向互联网的业务提供服务,运行SNAT。
- SLB 平行于 ESG 部署,连接到同一个 Transit VLAN 上。
- WEB VM 对外的 VIP 在两个站点都被宣告,但是 GSLB 配置为 A/S 结构,保证 DNS 查询结构返回地址 20.1.1.1,即主站点的 VIP。
- Failover 时,DNS 查询结果是 30.1.1.1,即备份站点的 VIP。具体何时发生 Failover 取决于 GSLB 的健康检查算法
- 使用 GSLB 时,不需要调整 Prefix List 或者 断开 UDLR CVM 接口等操作。GLSB 来控制数据包 Ingress 流向。
- 除了面向互联网的业务流量外,其他流量都通过 NSX ESG传输,不经过 SLB。
其他需要考虑的
- 为了支持 Cross-VC,物理网络的 MTU 要修改为>=1600。
- 站点之间的 RTT 最大为 150ms。
- Universal Logical Switch 不能做二层桥接。
- Universal DFW 只支持使用 IP Set、MAC Set、Security Groups(包含 IP Set和 MAC Set)来做防火墙策略。
- Universal 对象不支持第三方服务 insertion。
- Universal Logical Entities 不支持 Endpoint 安全。
- 通过路由宣告或者 GSLB 来控制 Ingress 流量相互不冲突。很多设计中两者可以共存。共用时,部分流量使用 GSLB 来保护业务网络连续性,剩余的使用路由宣告保护。
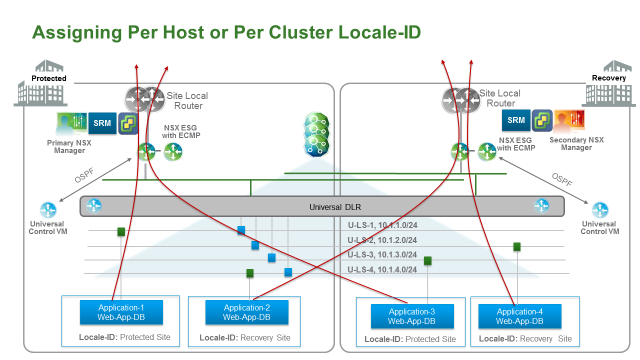
- 使用 Locale-ID 最小的颗粒度为每主机。因此在多个应用运行在同一台主机的情况下,这多个应用需要共享一个 Locale。
- 下例中,Application 1 和 Application 2在同一个物理站点,但是使用不同的 Locale-ID,因此他们不允许运行在同一台主机(或集群,如果Locale-ID基于Cluster设置)。同理 Application 3 和 4 也不能在同一台主机。
参考资料
【Disaster Recovery with NSX and SRM】