摘要:在上篇OSPF在MA网络下收敛时间时,提到了NSX的收敛时间,刚好这次有机会进行了关于NSX更为细致的测试,发现 NSX 并不能只根据那篇文章最后的总结,修改OSPF hello dead时间就行,事实更为复杂
这次进行了两种设计的测试,一种是Edge HA,一种是DLR开启ECMP+多个Edge。
Edge HA + OSPF
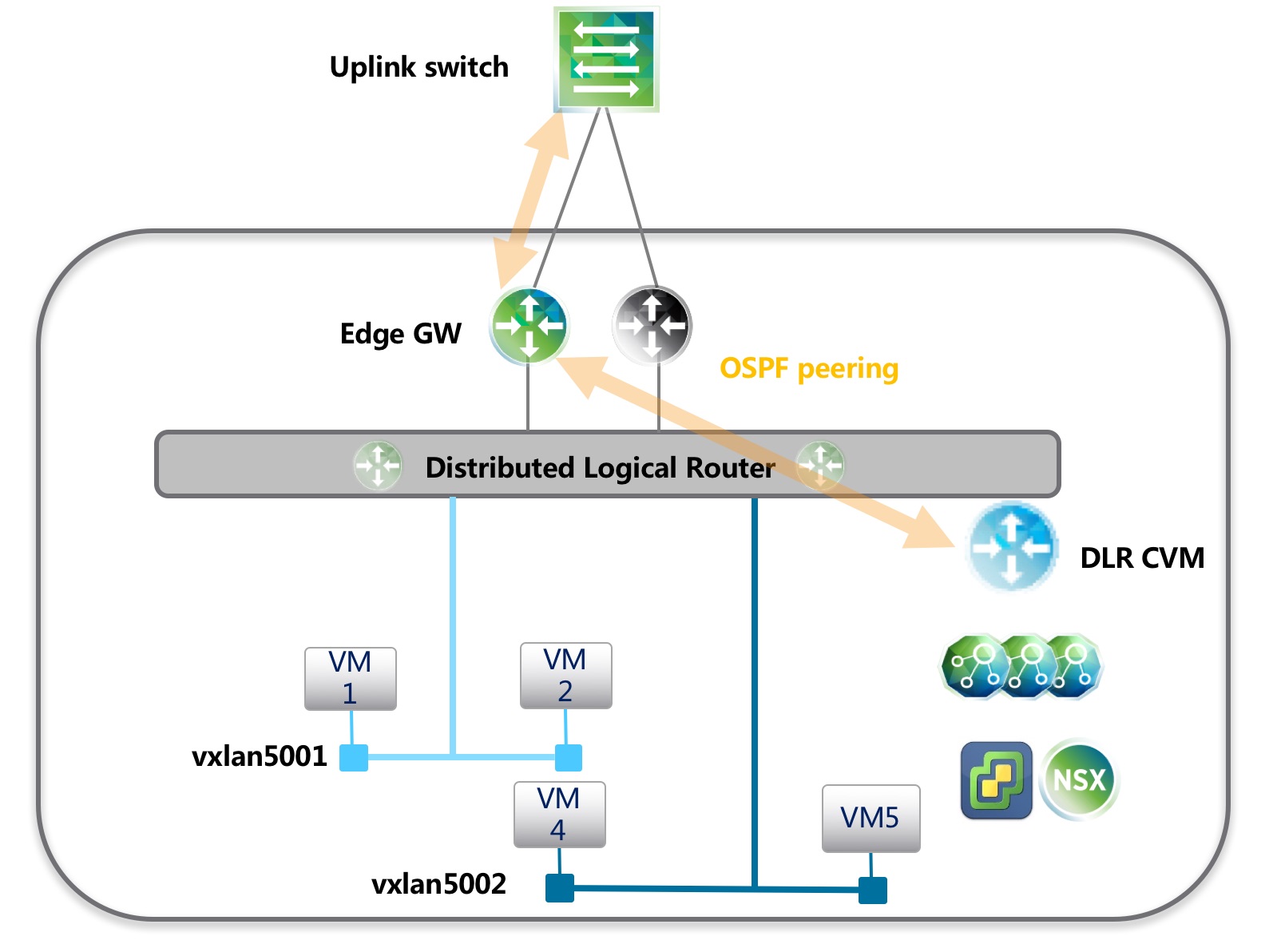
拓扑如上,这是最简单的一种NSX网络结构,网络结构简单,排错方便,ESG和DLR CVM都可以通过自带的HA功能来保证冗余,避免故障出现,VMware 建议 Edge 的 HA 超时时间不低于9s,也就是在Active Edge发生故障时,理论上最短7秒就会进行HA切换(每2s发送一个心跳检测),然后流量转发正常。
为了防止是DLR CVM故障,也可以通过HA来预防,NSX 6.3.x DLR HA时间默认为6秒。理论上DLR CVM的故障并不会引起主机上数据层面路由转发,此时流量转发应该是正常的。(6.2.x版本DLR心跳为15s时,可能引起Edge和DLR OSPF邻居断开,Edge 没有去往DLR的路由,通过改大OSPF dead时间能解决此问题)
在新版本NSX测试中发现如果DLR 运行了OSPF动态路由协议,则DLR CVM的HA后会重新和Edge建立邻居关系,此时会有短暂网络中断,测试中断时间在4s左右,猜测是Edge上FIB表有刷新操作。
解决以上两个问题的办法很简单,在Edge上加到DLR以及内部VM网络的静态路由。实际上,上图的网络拓扑完全可以在Edge和DLR之间运行静态路由协议,DLR 只需要配置到Edge的默认路由。Edge配置到内部VM网络的静态路由,并通过OSPF重发布静态路由发送路由信息给外部交换机。
在这种网络结构中,需要改大OSPF的Hello Dead时间(建议30,120),让路由在DLR CVM HA期间不变动,数据转发正常。
上图网络结构的限制是只有一个Edge,能提供的南北流量有上限。VMware建议如果Edge上需要启用NAT等需要保持流量来回路径一致的功能时,使用这样的网络结构。而对于普通的只有路由的网络,采用多个Edge做ECMP更好。
多Edge做ECMP
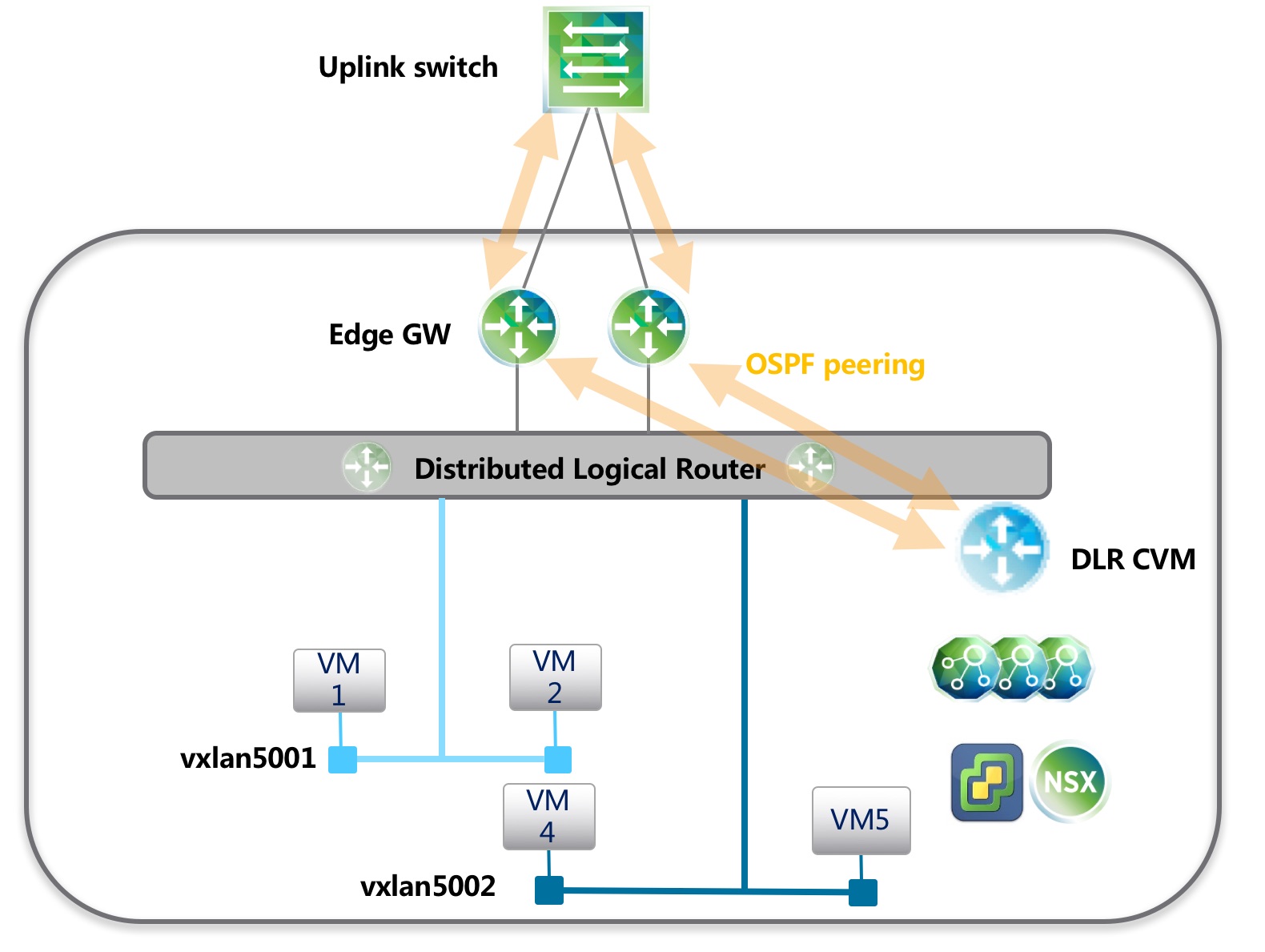
如果使用ECMP,DLR最大支持8条等价上行路径。且DLR只能有一个OSPF上行链路,所以在这样的结构下,DLR和多个Edge相连只能使用一个网段。
使用这种拓扑时,如果使用静态路由协议,则外部物理交换机的配置会比较复杂,需要配置IP SLA来检查Edge的健康状态,如果发现Edge故障后修改本地的静态路由。当外部交换机有多个时,配置量又会翻倍。
如果使用OSPF,如果按照默认OSPF配置,Dead时间未40s,一旦某个Edge出现故障,则部分虚拟机网络可能中断40s,为了尽可能快地让外部交换机检测到Edge故障,需要将Edge和DLR之间Hello Dead时间改为1,3秒。ESG 与 DLR CVM的 Hello Dead 时间也需要修改为1,3。
理想状态下,Edge的故障引起的丢包只是5s左右,但如果同时有其他控制层的组件故障,会有些未知的风险。
在做ECMP时,VMware建议不要将DLR CVM和其ECMP邻居放在同一台主机上。一旦放在一起,DLR CVM和Edge同时故障后,会有部分主机继续向不可用的Edge转发流量,只有在DLR CVM通过HA恢复后重新学习路由才能恢复网络。
衍生话题:延展集群+NSX
延展集群是指逻辑上的一个集群,在物理上主机存放在不同的位置,简单的容灾环境可能是这样的结构。
VMware VSAN有个功能叫延展集群,可以实现两地存储双活,这时候如果使用NSX的VXLAN功能,也可以做到不依赖物理交换机实现大二层,虚拟机则可以在两个数据中心都运行,节省资源并提供较高的故障切换级别。
NSX架构限制,对于一个VXLAN只能有一对DLR CVM,三个Controller和若干Edge gateway。这三个角色是运行在延展集群的哪个物理位置成了难题。因为这时候,一个物理数据中心是一个故障域。
在延展集群下依然可以有两种部署,一种是用Edge HA完成网络故障切换,一种是通过ECMP来完成。
1、Edge HA时,需要配置两个Uplink,一个Uplink关联本数据中心(假设为A)物理交换机,和A数据中心物理交换机互为邻居,另外一条设置为和B数据中心物理交换机连接,当此Edge在数据中心A运行时,只能和A的物理交换机通信,所有流量通过A的物理交换机出;Edge在B运行时,只能和B的物理交换机通信。
我们假设 Edge 在A为活动,Controller运行在A,如果数据中心A故障,Edge可以发生HA,但是Edge运行主机位置有变动,需要Controller更新主机的VTEP等表,所以Controller不能和Active Edge 运行在同一数据中心。
这样的结构,DLR和Edge用静态路由最为稳定。
2、如果使用ECMP,则必须在A和B两个数据中心均运行Edge,每个Edge只设置一个Uplink和其本地物理交换机通信。DLR 启用ECMP,使用动态路由协议帮助检查Edge的健康状态,进行路由收敛。Hello Dead值可以根据前文提示更改。
这样的网络结构,DLR必须有Control VM存在,且同时需要Controller完成路由更新。
让两个数据中心的Edge都发送流量会存在风险,因为Controller只能放在A或者B,同一个数据中心的Edge和Controller都出现问题时会有部分虚拟机通信中断。
解决办法依然有两个:一个是优化进出流量路径,做到本地虚拟机本地转发(Egress optimization),从本地物理交换机返回虚拟机(ingress optimization)。实现前者可以通过NSX 的Local ID来实现,但笔者在6.2.4环境下测试并不理想,配置完Local ID没几分钟,两个数据中心的路由表又被同步成一样的了,所有流量只能从A数据中心出或者B数据中心出。进流量优化则需要负载均衡设备参与才能实现。
另一种是只让流量从单个数据中心出,也就是只让一个数据中心的Edge转发流量,另外一个数据中心Edge做备份。可以很容易通过OSPF cost来调整来实现此功能。这样的设计下,也是Controller不能和Active Edge 运行在同一数据中心,且DLR CVM也不能和Active Edge运行在同一数据中心。
按照以上的所有介绍优化后,NSX组件的故障引起的网络中断时间可以控制在10秒内,完全可以满足实时性要求不是很高的业务。对于业务连续性高的应用,或许用应用集群+负载均衡的方式实现更为理想。