摘要:在做vSphere时一个常用的功能是HA,HA包含主机故障检测、虚拟机异常检测。关于虚拟机相关参数调整的介绍较多,但是对于主机高级参数以及主机故障后HA如何工作的文章较少,本文章主要介绍主机故障时HA工作机制以及虚拟机在多久应该可以重启/恢复
在HA中,主机有两种觉得,Master 以及 Slave角色,这两种角色主机故障时,虚拟机恢复时间是不同的
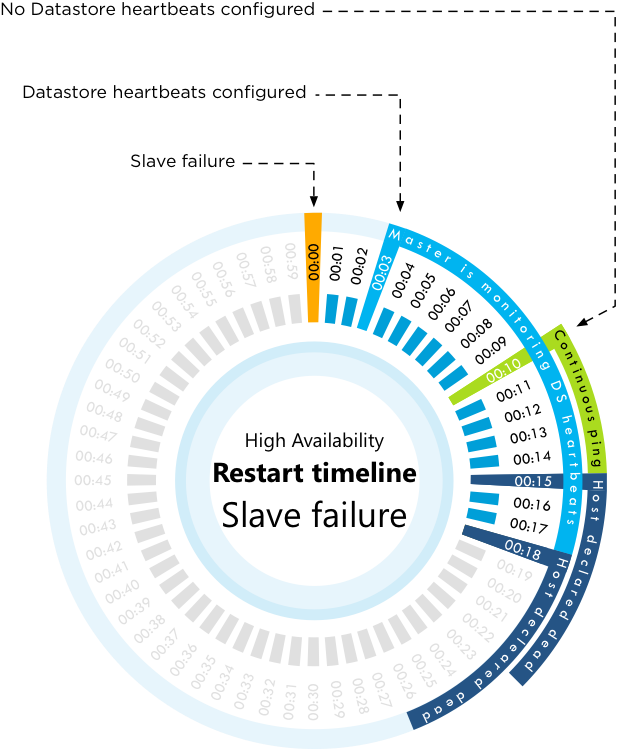
1、Slave 主机发生故障
Slave 发生故障时,时间轴如下:
- T0 – Slave 主机故障发生。
- T3s – Master主机开始检查存储心跳,持续15秒。
- T10s – 主机被宣告为不可达,Master 主机会ping 故障主机的网关地址,持续ping 5秒钟。
- T15s – 如果没有配置存储心跳检查,则主机会被宣告为故障。
- T18s – 如果配置了存储心跳,则主机被宣告故障。
Master主机会监控Slave主机的网络心跳,如果Slave发生故障,则Master会收不到Slave的心跳,我们将此时标记为T0。如果配置HA时配置了存储心跳,则从第三秒开始,Master会检查存储心跳,持续15秒(所以配置了存储心跳后,理论上18秒后才会进行虚拟机重启)。在第10秒,如果网络和存储心跳检查都失败,则主机被标记为“不可达”。在第10秒,Master主机同时会ping Slave主机的管理网络网关,持续ping 5秒钟。到第15秒,如果没有配置存储心跳,则主机被标记为故障, 虚拟机会进行重启操作。到第18秒,如果配置了存储心跳,则主机被标记为故障。
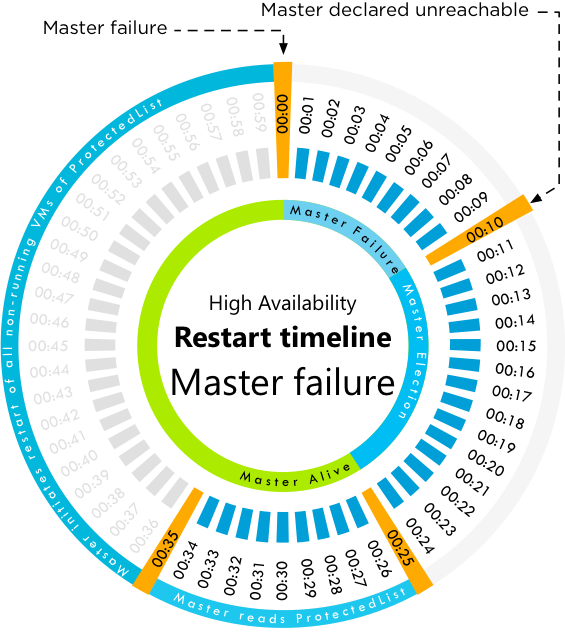
2、Master主机故障
- T0 – Master 主机故障
- T10s – 新Master 选举
- T25s – 新Master 选举完成,并读取保护列表 protectedlist。
- T35s – 新Master 开始重启在保护列表中,但是未运行的虚拟机。
如果Slave主机未从Master收到网络心跳,我们将此时间定义为T0。每个集群必须有一个Master,因此Slave主机们在T10进行选举,选举过程需要15秒完成,因此到了T25。在25秒时,新的Master主机读取保护列表,列表中包含受保护的VM列表。在第35s时,Master重启那些在受保护列表中但未运行的虚拟机。
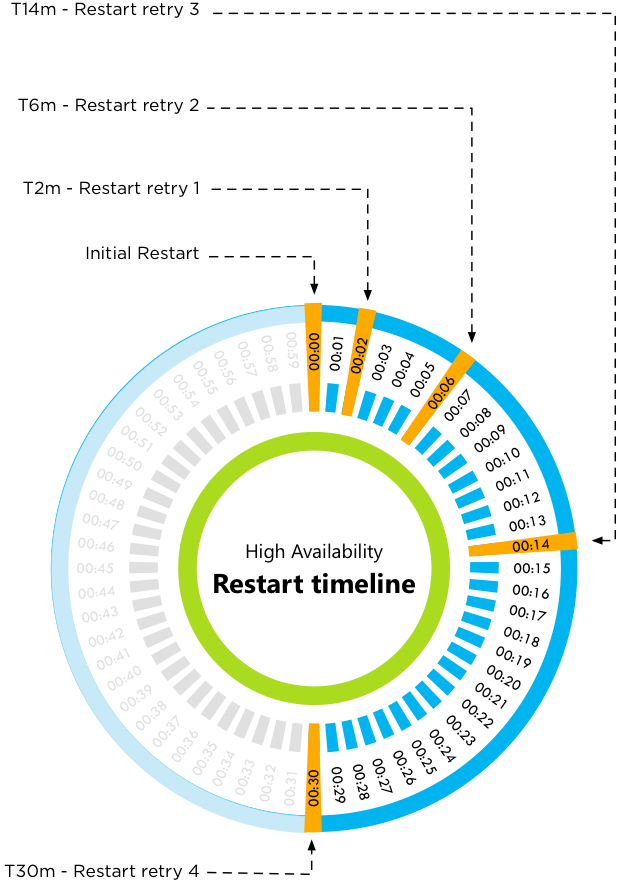
3、虚拟机启动时间轴
最后,是虚拟机如何被Master主机启动。
- T0 – 初始重启
- T2m – 第一次重试重启
- T6m – 第二次重试重启
- T14m – 第三次重试重启
- T30m – 第四次重试重启
在Master主机第一次启动虚拟机时,我们将其标记为T0分钟。如果初始启动失败,则在两分钟后进行第一次重试,6分钟后进行第二次重试,依图依次。默认最大重启次数为5次,此值可以通过vCenter高级参数 “das.maxvmrestartcount” 来修改
总结
按照上文的描述,虚拟机重启时间最短可能为20秒左右,最长可能达到30分钟。在实际测试中,我们得出的平均时间是2分30秒,此时间应该刚好是主机故障后,Master第一次重试启动后时间。